
この記事では応用情報で出題されるAIについてIT初心者にも分かりやすく解説します。
機械学習
- 機械学習では大量のデータからAIが学習し、パターンやルールを発見する
- 教師あり学習は機械学習の一種で、入力データとそれに対する答えをAIに与えて予測モデルを作る
- 回帰は教師あり学習の一種で、入力データから連続した値を予測する
- 分類は教師あり学習の一種で、入力データからカテゴリを予測する
- 2クラス分類モデルとは、2種類のカテゴリに分類するモデル
- 過学習は、学習データに対しては精度が高いが、未知のデータに対しては精度が低い状態
- 交差検証は、用意したデータを複数のグループに分け、一部のグループを学習用に、残りのグループを検証用に使う、ということをグループを入れ替えながら行い、モデルの検証を行う手法
- ROC曲線は、2クラス分類モデルを評価する方法で、真陽性率と偽陽性率の関係性を示す
ディープラーニング
- ディープラーニングでは、人間の神経細胞に似たニューラルネットワークを取り入れて複雑な判断をする
応用情報ではAIに関する問題が頻出します。是非最後までご覧ください。
機械学習
機械学習とは、データを分析する手法の一つで、大量のデータからAIが学習し、パターンやルールを発見する方法です。
機械学習の手法には「教師あり学習」「教師なし学習」「強化学習」の3つあります。
ここ最近では「教師あり学習」しか出題されていないので、教師あり学習を紹介します。
教師あり学習
教師あり学習とは、入力データとそれに対する答えを与えて学習させ、AIが入力データから答えを導けるようにする手法です。
教師あり学習には更に回帰と分類の2つ種類があります。
回帰
回帰では入力データから値を予測します。回帰は連続した値が答えになるのが特徴です。
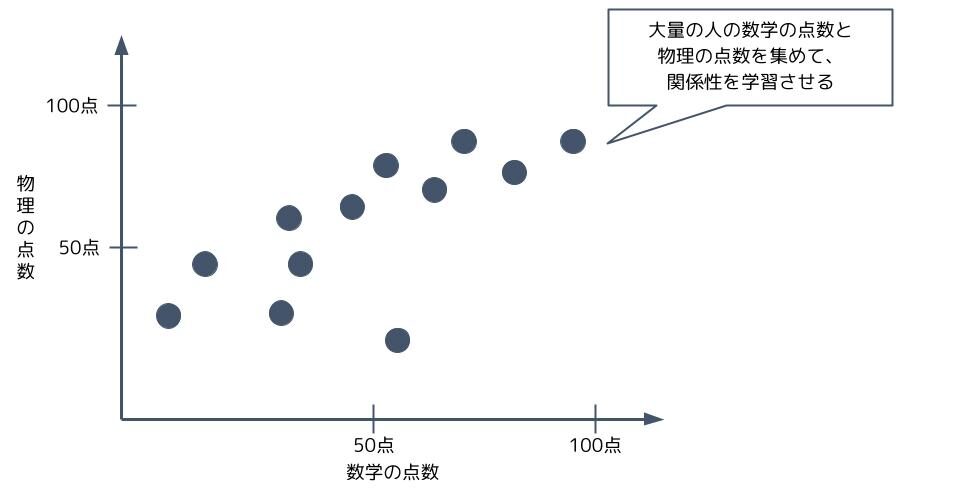
例えば、数学の点数から物理の点数を予測するのが回帰ですね。
「数学のテストが70点だったA君は物理のテストで65点でした」
「数学のテストが40点だったB君は物理のテストで41点でした」
というデータをAIに大量に与えることで数学の点数と物理の点数の関係を学習させます。
そして、「数学のテストが54点だったZ君は物理で何点取るか?」を予測させるのが回帰です。
分類
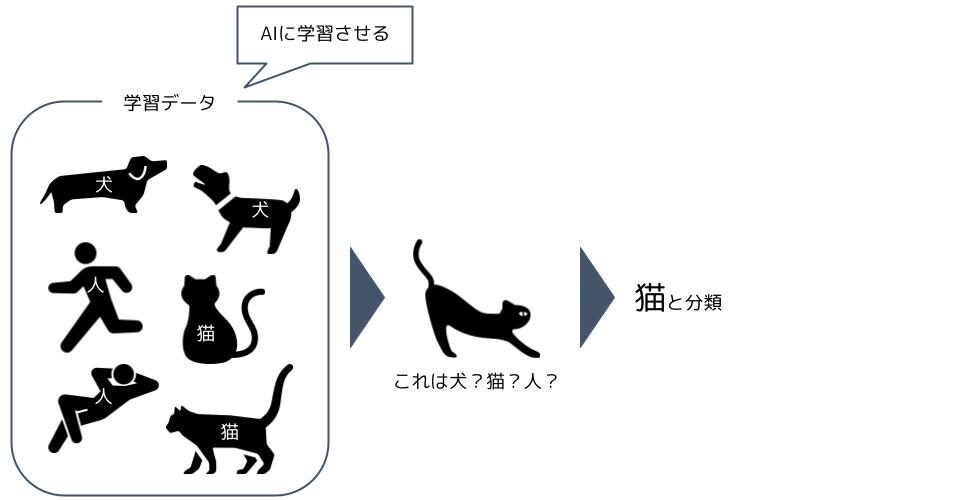
分類では入力データからカテゴリを予測します。分類は例えば、メールがスパムか非スパムかの分類や、動物が猫か犬か人かの分類を予測するのが特徴です。要するに、Yes/Noが答えになるような学習が分類ですね。
「この画像は猫です」「この画像は人です」と言う感じで、大量の画像データを答えと共にAIに与え、AIは画像から答えのパターンを学習します。学習の時、例えば、「二足歩行していたら答えは人である」と特徴も教えてあげます。そうすることで、AIは与えられた画像データが猫か犬か人か判断出来るようになります。
2クラス分類モデル
2クラス分類モデルとは、「このメールはスパムか非スパムか?」や「この動物は犬か猫か?」のようにデータを2つのカテゴリに分類するモデルです。
過学習
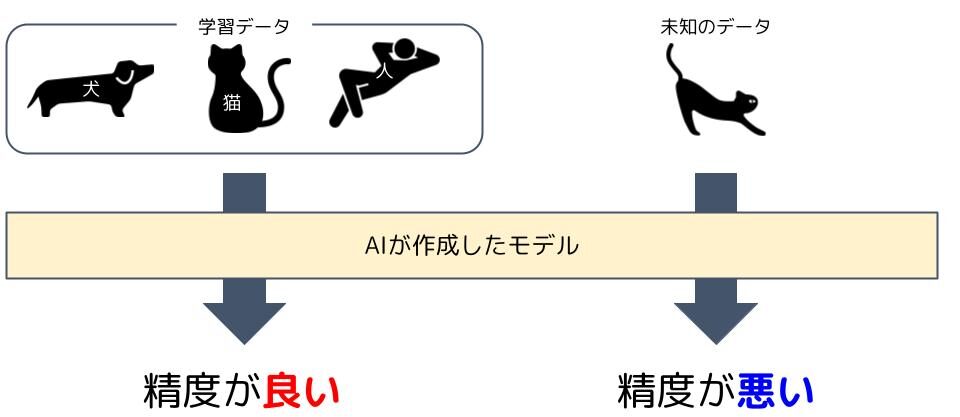
AIは学習したデータから答えを予測するモデルを作ります。
しかし、そのモデルが学習データには対しては良い精度を発揮するが、未知のデータに対しての精度が良くないという状態になることがあり、これを過学習と呼びます。
AIが作ったモデルも常に完璧という訳では無いので、人間が評価してあげる必要があります。教師あり学習で使われる評価方法に交差検証とROC曲線があります。
交差検証
AIが作ったモデルを検証するには、学習データと検証データを用意する必要があります。
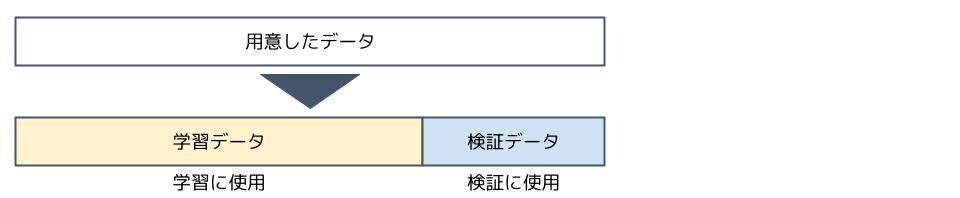
しかし、1回の検証で、そのモデルを正しく評価出来るかと言われると微妙な所があります。その時に使った検証データが偶々予測しやすいデータだった、みたいなことがありますからね。
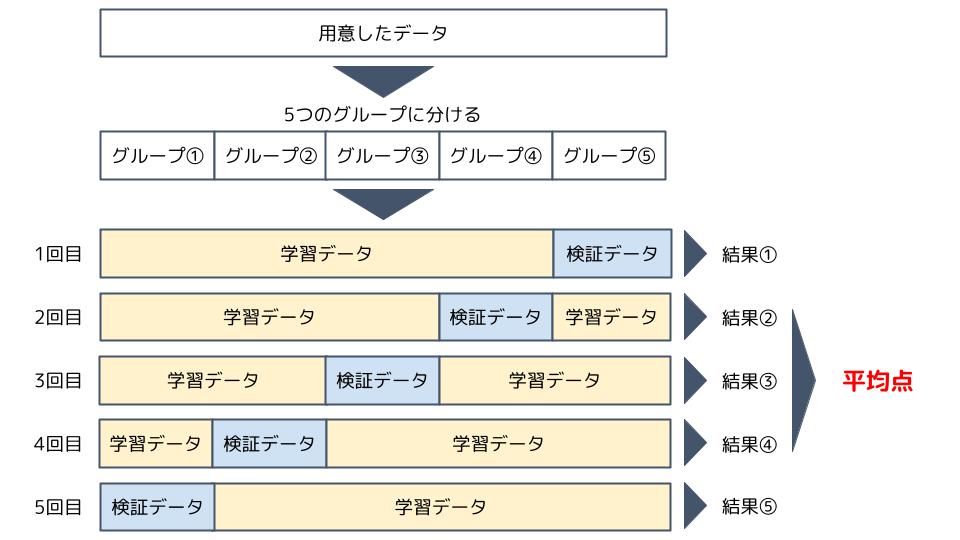
そこで、交差検証では、用意したデータを複数のグループに分け、一部のグループを学習用に、残りのグループを検証用に使う、ということをグループを入れ替えながら行います。
1回目ではグループ①~④からモデルを作り、グループ⑤で検証して結果を確認します。
次に1回目で作ったモデルを一度リセットし、グループ①~③とグループ⑤からモデルを作り、グループ④で検証して結果を確認します。ということを5回繰り返し、それぞれの検証結果を平均することで、AIが作るモデルを正しく評価します。
ROC曲線
ROC曲線は2クラス分類モデルを評価する手法です。
「この画像は猫か?」を予測するモデルを例に2クラス分類モデルを考えてみましょう。
AIの予測結果は次の4つに分類できます。
- 猫を正しく猫だと予測する:真陽性
- 猫なのに誤って猫ではないと予測する:偽陰性
- 猫ではない画像を正しく猫ではないと予測する:真陰性
- 猫ではない画像なのに誤って猫だと予測する:偽陽性

ところで、2クラス分類モデルではどのように猫かどうかを判断するのでしょうか?
猫の画像をモデルに読み込ませると、猫っぽさが64点だと判定しました。
60点以上なら猫と設定すれば、モデルはこの画像を猫だと判定しますし、
70点以上なら猫と設定すれば、モデルはこの画像を猫ではないと判定します。
つまり、何点以上なら猫とするのか、の設定によって答えは変わってきてしまいます。
この時設定した点数を閾値と言います。

閾値を高くすれば判断基準が高くなるので、猫の画像なのに猫ではないと判断してしまう可能性が高くなります(真陽性率が低くなる)。しかし、猫の画像ではないのに猫だと判断する可能性も低くなります(偽陽性率が低くなる)。
逆に閾値を低くすれば判断基準が低くなるので、真陽性率は高くなりますが、偽陽性率も高くなります。
閾値を0点から100点まで色々設定した時の真陽性率と偽陽性率の関係を表したグラフがROC曲線です。
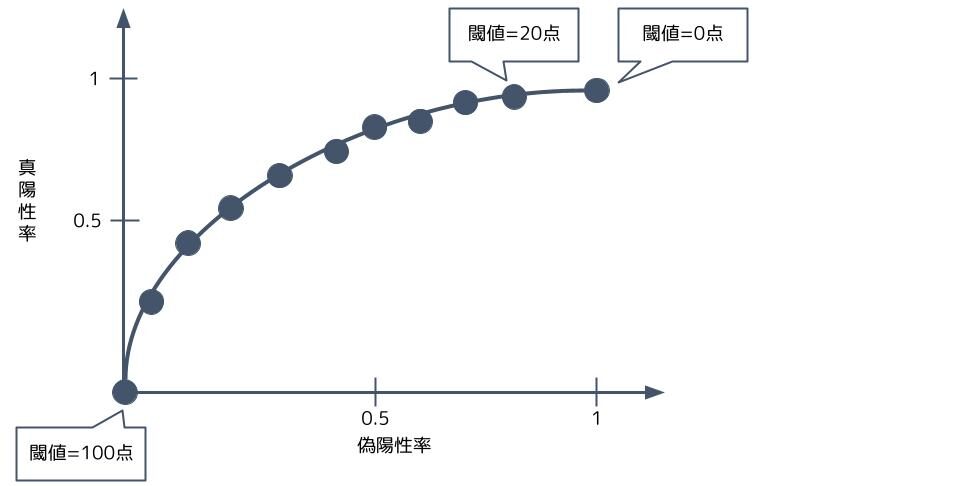
閾値が0点のとき、全ての画像を猫だと判断してしまうので、猫の画像を猫だと判断する確率(真陽性率)は100%ですが、猫ではない画像を猫だと判断する確率(偽陽性率)も100%となってしまいます。同じように閾値が100点のとき、真陽性率と偽陽性率は共に0%となります。これはどのモデルでも同じです。
ここから閾値を変えていくと、どうなるかを示したのがROC曲線ですね。
閾値が20点のとき、猫の画像を猫だと判断する確率(真陽性率)が90%、猫ではない画像を猫だと判断する確率(偽陽性率)が80%になる・・・というのを閾値を変えて調べていきます。
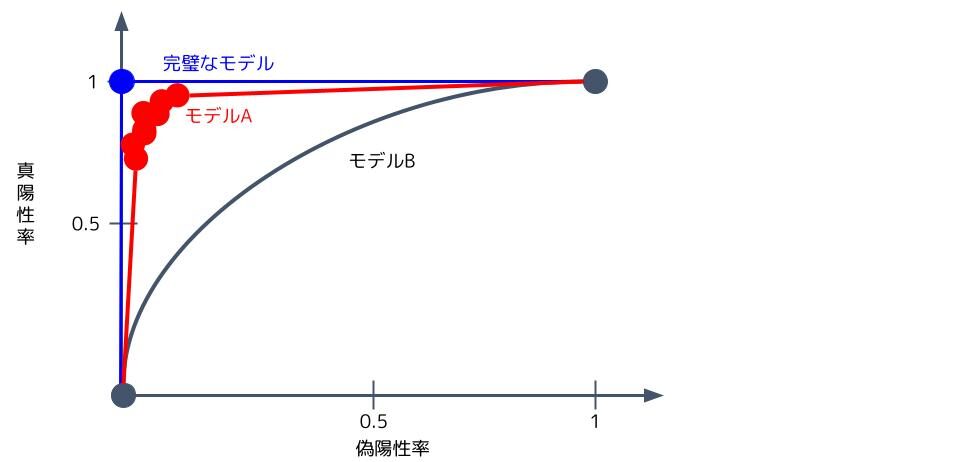
ちなみに、完璧なモデルは閾値をどう変化させても真陽性率=1、偽陽性率=0となります(青の完璧なモデル)。良いモデルは閾値をどう変化させても真陽性率が高く、偽陽性率が低くなります(赤のモデルA)。
グラフで見ると、完璧なモデルに形が近付く程、良いモデルと言えるとことが分かります。
ディープラーニング
機械学習では「二足歩行していたら人間である」のような特徴量を開発する必要がありますが、ディープラーニングでは特徴量の開発を必要としません。AIが自動で有用な特徴量を学習していきます。
ディープラーニングでは、人間の神経細胞に似たニューラルネットワークを取り入れて、複雑な判断が出来るようにしています。
応用情報技術者試験での出題例
令和6年度秋期問2
応用情報技術者
午前試験 令和6年度秋期問2
AIにおける教師あり学習での交差検証に関する記述はどれか。
ア 過学習を防ぐために,回帰モデルに複雑さを表すペナルティ項を加え,訓練データへ過剰に適合しないようにモデルを調整する。
イ 学習の精度を高めるために,複数の異なるアルゴリズムのモデルで学習し,学習の結果は組み合わせて評価する。
ウ 学習モデルの汎化性能を高めるために,単一のモデルで関連する複数の課題を学習することによって,課題間に共通する要因を獲得する。
エ 学習モデルの汎化性能を評価するために,データを複数のグループに分割し,一部を学習に残りを評価に使い,順にグループを入れ替えて学習と評価を繰り返す。
正解は”エ”
交差検証では、データを複数のグループに分割し、一部を学習用に、残りを検証用にします。これをグループを入れ替えながら行うことで、検証の精度を上げていきます。
ちなみに、汎化性能とは、未知のデータから正しい答えを導ける力のことです。
令和6年度春期問3
応用情報技術者
午前試験 令和6年度春期問3
AIにおけるディープラーニングに関する記述として,最も適切なものはどれか。
ア あるデータから結果を求める処理を,人間の脳神経回路のように多層の処理を重ねることによって,複雑な判断をできるようにする。
イ 大量のデータからまだ知られていない新たな規則や仮設を発見するために,想定値から大きく外れている例外事項を取り除きながら分析を繰り返す手法である。
ウ 多様なデータや大量のデータに対して,三段論法,統計的手法やパターン認識手法を組み合わせることによって,高度なデータ分析を行う手法である。
エ 知識がルールに従って表現されており,演繹手法(えんえきしゅほう)を利用した推論によって有意な結論を導く手法である。
正解は”ア”
ディープラーニングでは、人間の神経細胞に似たニューラルネットワークを使い、複雑な判断をします。
令和5年度春期問3
応用情報技術者
午前試験 令和5年度春期問3
AIにおける機械学習で,2クラス分類モデルの評価方法として用いられるROC曲線の説明として,適切なものはどれか。
ア 真陽性率と偽陽性率の関係を示す曲線である。
イ 真陽性率と適合率の関係を示す曲線である。
ウ 正解率と適合率の関係を示す曲線である。
エ 適合率と偽陽性率の関係を示す曲線である。
正解は”ア”
ROC曲線は真陽性率と偽陽性率の関係を示す曲線です。
令和4年度秋期問4
応用情報技術者
午前試験 令和4年度秋期問4
AIにおける過学習の説明として,最も適切なものはどれか。
ア ある領域で学習した学習済みモデルを,別の領域に再利用することによって,効果的に学習させる。
イ 学習に使った訓練データに対しては精度が高い結果となる一方で,未知のデータに対しては精度が下がる。
ウ 期待している結果とは掛け離れている場合に,結果側から逆方向に学習させて,その差を少なくする。
エ 膨大な訓練データを学習させても効果が得られない場合に,学習目標として成功と判断するための報酬を与えることによって,何が成功か分かるようにする。
正解は”イ”
過学習では学習データに対して精度が良くなり、未知のデータに対しては精度が悪くなります。
令和3年度秋期問3
応用情報技術者
午前試験 令和3年度秋期問3
AIにおけるディープラーニングに最も関連が深いものはどれか。
ア ある特定の分野に特化した知識を基にルールベースの推論を行うことによって,専門家と同じレベルの問題解決を行う。
イ 試行錯誤しながら条件を満たす解に到達する方法であり,場合分けを行い深さ優先で探索し,解が見つからなければ一つ前の場合分けの状態に後戻りする。
ウ 神経回路網を模倣した方法であり,多層に配置された素子とそれらを結ぶ信号線で構成されたモデルにおいて,信号線に付随するパラメタを調整することによって入力に対して適切な解が出力される。
エ 生物の進化を模倣した方法であり,与えられた問題の解の候補を記号列で表現して,それらを遺伝子に見立てて突然変異,交配,とう汰を繰り返して逐次的により良い解に近づける。
正解は”ウ”
ディープラーニングでは、人間の神経細胞に似たニューラルネットワークを使い、複雑な判断をします。
