
この記事ではパイプライン制御とマルチプロセッサについてIT初心者にも分かりやすく解説します。
パイプライン制御
- パイプライン制御では単独のCPU内で複数の命令を同時並行で処理する。
- 処理に分岐がある場合、次に実行する命令を予測することを分岐予測と言い、分岐予測に基づいて先に命令を実行することを投機実行と言う。
- 依存関係がない命令をあらかじめ1つの命令にまとめる技術をVLIWと言う。
マルチプロセッサ
- CPUとプロセッサは同じ意味の言葉
- マルチプロセッサは1つのコンピュータ内に複数のプロセッサを搭載して処理効率を上げる技術
- 密結合マルチプロセッサは複数のプロセッサが1つの主記憶装置を共有する技術。主記憶装置へのアクセスが同時に発生すると処理効率が比例して上がらなくなる。
- プロセッサ数を2倍、3倍と増やしても、並行処理できない命令がある場合、処理効率は2倍、3倍と増えていかずに限界が来る。これをアムダールの法則と言う。
応用情報ではパイプライン制御とマルチプロセッサに関する問題がたまに出ます。是非最後までご覧ください。
命令実行サイクル
CPUはユーザから入力された命令を下の流れで実行していきます。
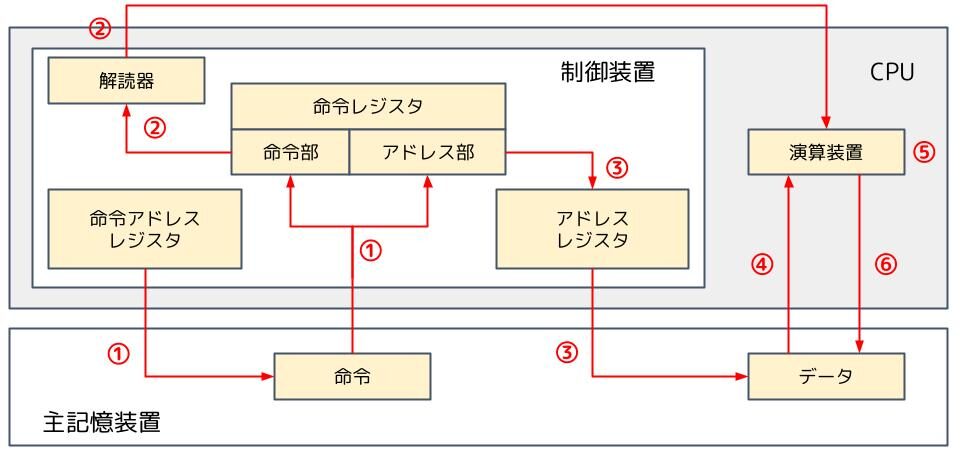
- 命令フェッチ:主記憶装置から命令を取り出して命令レジスタに格納します
- 命令の解読:解読器が命令の解読を行い、演算装置に指示します
- 実行アドレス計算:演算に必要なデータのアドレスを計算します
- オペランド読出し:データを主記憶装置から取り出して演算装置に送ります
- 命令の実行:演算装置が演算を実行します
- 演算結果格納:演算結果を主記憶装置に格納します
下の記事で命令実行サイクルについて詳しく解説しています。

パイプライン制御
CPUが命令を実行する方式には、1つずつ命令を実行していく逐次制御と
複数の命令を並行して実行するパイプライン制御があります。
逐次制御では命令①の演算結果格納が終わってから、命令②の命令フェッチを実行します。

しかし、命令フェッチと演算結果格納で使う回路は違うので、命令①が終わるまで命令②の処理を始めないのは非効率ですよね。そこで、複数の命令を並行して実行するようにしたのがパイプライン制御です。
パイプライン制御では命令①の命令フェッチが終われば、命令②の命令フェッチを始めてしまいます。このように命令を並行処理することで、処理の高速化を実現します。

分岐予測と投機実行
処理には分岐があるものです。例えば、「命令①の実行結果がAの場合は命令②を実行して、Bの場合は命令③を実行する」のように。
しかし、パイプライン制御では命令を次々と処理していくので、命令①の実行結果を待つのか?という問題点が出てきます。
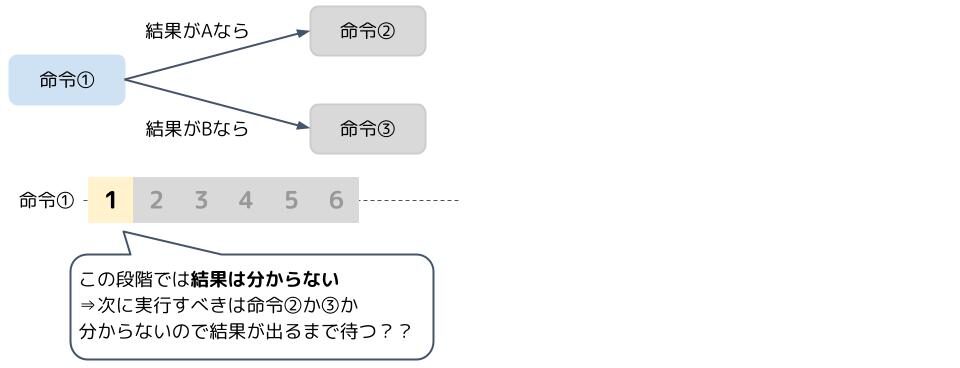
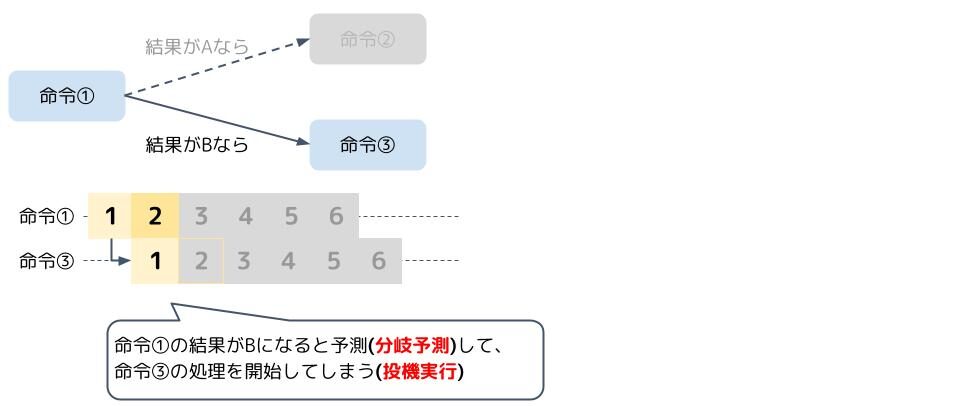
当然待つのは嫌なので、分岐の結果、次の命令がどれになるのかを予測してしまいます。これを分岐予測と言います。そして、分岐予測に基づいて、先に命令を処理してしまいます。これを投機実行と言います。
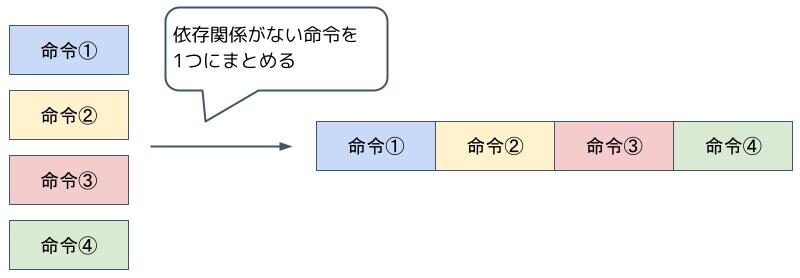
VLIW(Very Long Instruction Word)
VLIWは、同時に実行可能な複数の命令を1つの命令にまとめて実行させる手法です。
分岐予測のところでも見たように、処理する命令には前後関係のような依存関係がある命令もあります。CPUは命令同士に依存関係があるかどうか判断しながら命令を実行していくので大変です。
そこで依存関係がない複数の命令を、あらかじめ1つにまとめておき、CPUが判断する回数を減らしておこうとしたのがVLIWです。
マルチプロセッサ
パイプライン制御は単独のCPUの処理効率を上げる方法でしたが、CPU1つでは性能を向上するのに限界がありました。そこで、複数のCPUを搭載して性能を向上させる技術が注目されるようになりました。一つのパソコンの中に複数のCPUを搭載するシステムをマルチプロセッサシステムと呼びます。

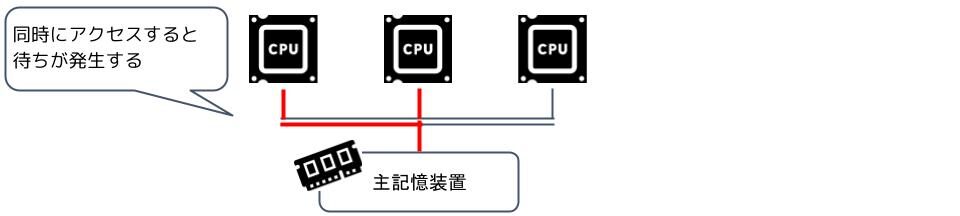
マルチプロセッサでは複数のCPUが登場するので、主記憶装置との関係が問題になります。
現在多く使われているマルチプロセッサでは、複数のCPUが一つの主記憶装置を共有します。これを密結合マルチプロセッサと呼びます。
CPUとプロセッサの違い
結論から言うとCPUとプロセッサに違いはありません。
厳密には、プロセッサはデータ処理や制御を行う装置全般のことで、CPUはコンピュータ内部の演算装置と制御装置です。でも、これって同じことですよね。
なので、CPU=プロセッサで問題ありません。
マルチプロセッサの話をするときは、プロセッサを使う多いので、プロセッサという言葉を使っていきます。
密結合マルチプロセッサ
密結合マルチプロセッサでは、複数のプロセッサが一つの主記憶装置を共有します。

複数のプロセッサが並行して処理するので処理効率は上がりますが、一つの主記憶装置を取り合うので、アクセスが競合した場合はそこまで処理効率が上がりません。
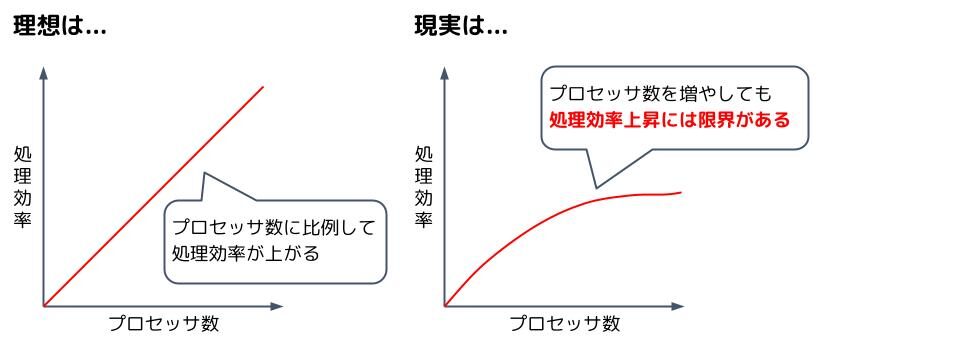
アムダールの法則
プロセッサの数を2倍、3倍と増やすと、その分、処理効率も2倍、3倍と上がっていくように思いますが、実際はそうはなりません。密結合マルチプロセッサで見たように、主記憶装置へのアクセスの競合などが原因で同時並行で実行できる処理には限界があるからです。
このようにプロセッサ数を増やしても処理効率に限界があることを示したものがアムダールの法則です。
応用情報技術者試験での出題例
令和6年度春期問14
応用情報技術者
午前試験 令和6年度春期問14
1台のCPUの性能を1とするとき,そのCPUをn台用いたマルチプロセッサの性能Pが,
P=\(\displaystyle \frac{n}{1+(n-1)a}\)
で表されるとする。ここで,aはオーバーヘッドを表す定数である。例えば,a=0.1, n=4とすると,P≒3なので,4台のCPUから成るマルチプロセッサの性能は約3になる。この式で表されるマルチプロセッサの性能には上限があり,nを幾ら大きくしてもPはある値以上には大きくならない。a=0.1の場合,Pの上限は幾らか。
ア 5 イ 10 ウ 15 エ 20
正解は”イ”
プロセッサの数を増やしても性能の向上には限界があります。
この問題では性能を次の式で表していますが、この式を使って限界値を求めていきます。
P=\(\displaystyle \frac{n}{1+(n-1)a}\)
プロセッサ数が1のとき(n=1)
P=\(\displaystyle \frac{n}{1+(n-1)a}\)=1となります。
つまり、プロセッサ数が1つのときは性能1です。
プロセッサ数が4のとき(n=4)
P=\(\displaystyle \frac{4}{1+3×0.1}\)≒3となります。
つまり、プロセッサ数を4つにしても、性能は3倍にしかならないということですね。
プロセッサ数が10のとき(n=10)
P=\(\displaystyle \frac{10}{1+9×0.1}\)≒5.3となります。
プロセッサ数が100のとき(n=100)
P=\(\displaystyle \frac{100}{1+99×0.1}\)≒9.2となります。
プロセッサ数が1000のとき(n=1000)
P=\(\displaystyle \frac{1000}{1+999×0.1}\)≒9.9となります。
プロセッサ数が10000のとき(n=10000)
P=\(\displaystyle \frac{10000}{1+9999×0.1}\)≒9.9となります。
nをこれ以上増やしてもPが10を超えることは無さそうですね。
よって、上限は10だと分かります。
ちなみに、オーバーヘッドとはCPUが処理を実行するときに発生する負荷のことです。
令和5年度秋期問9
応用情報技術者
午前試験 令和5年度秋期問9
パイプラインの性能を向上させるための技法の一つで,分岐条件の結果が決定する前に,分岐先を予測して命令を実行するものはどれか。
ア アウトオブオーダー実行
ウ 投機実行
イ 遅延分岐
エ レジスタリネーミング
正解は”ウ”
パイプライン制御において、分岐予測した命令を先に実行しておくことを投機実行と言います。
令和5年度春期問9
応用情報技術者
午前試験 令和5年度春期問9
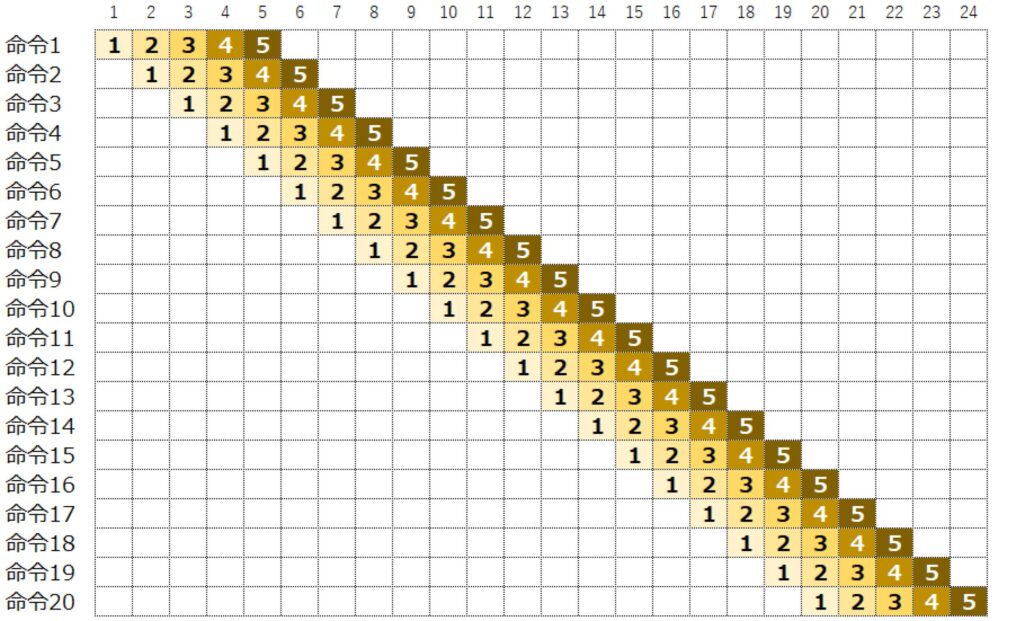
全ての命令が5ステージで完了するように設計された,パイプライン制御のCPUがある。20命令を実行するには何サイクル必要となるか。ここで,全ての命令は途中で停止することなく実行でき,パイプラインの各ステージは1サイクルで動作を完了するものとする。
ア 20 イ 21 ウ 24 エ 25
正解は”ウ”
20命令を実行した場合、下図のように24サイクル必要になります。
令和4年度春期問8
応用情報技術者
午前試験 令和4年度春期問8
プロセッサの高速化技法の一つとして,同時に実行可能な複数の動作を,コンパイルの段階でまとめて一つの複合命令とし,高速化を図る方式はどれか。
ア CISC イ MIMD ウ RISC エ VLIW
正解は”エ”
同時に実行可能な命令を1つにまとめる技術をVLIWと言います。
令和4年度春期問12
応用情報技術者
午前試験 令和4年度春期問12
プロセッサ数と,計算処理におけるプロセスの並列化が可能な部分の割合とが,性能向上へ及ぼす影響に関する記述のうち,アムダールの法則に基づいたものはどれか。
ア 全ての計算処理が並行化できる場合,速度向上比は,プロセッサ数を増やしてもある水準に漸近的に近づく。
イ 並列化できない計算処理がある場合,速度向上比は,プロセッサ数に比例して増加する。
ウ 並列化できない計算処理がある場合,速度向上比は,プロセッサ数を増やしてもある水準に漸近的に近づく。
エ 並行化できる計算処理の割合が増えると,速度向上比は,プロセッサ数に反比例して減少する。
正解は”ウ”
主記憶装置へのアクセスの競合などが原因で同時並行で実行できない処理がある場合、プロセッサ数を増やしても処理効率の向上には限界があります。よって、答えはウです。
